一次线上接口超时,我追了四个方向,最后什么都没查出来
一次线上接口超时,我追了四个方向,最后什么都没查出来
TL;DR 监控突然报了几十次接口超时,调用方数据不一致、告警刷屏。我从调用方日志、服务方日志、MySQL 慢 SQL、JVM Full GC 四个方向逐一排查,每一个方向都”看起来没问题”,但超时确实发生了。这篇文章记录的是一次没有结论的排查——以及我为什么觉得”没有结论”本身也值得写下来。
📌 本文要点
- 一个跨服务 RPC 调用超时,如何在调用方和服务方呈现完全不同的画面
- 为什么”DB 监控没有慢 SQL”不能反证”DB 没有问题”
- JVM 没有监控时,排查 STW 只能靠推理,而推理是靠不住的
- 当所有线索都断掉时,下一步该做什么
🌪️ 告警先到,原因后到
那天上午,监控先响了。
云平台 proxy 服务调用 gatewayapi 的 RPC 接口出现几十次超时,集中在几分钟内。
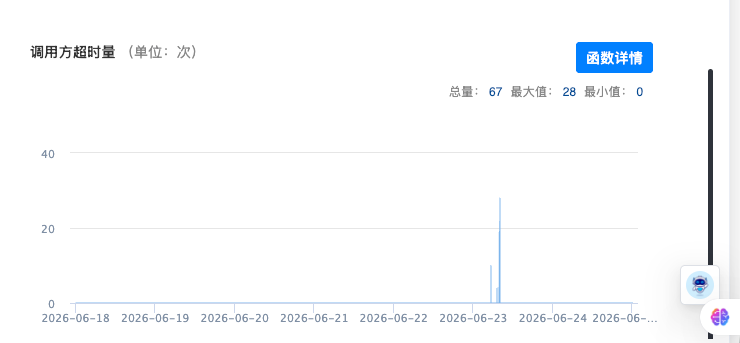
从监控上能清晰看到,异常时段出现了几十次超时,时间高度集中。proxy 是调用方,gatewayapi 是服务方——proxy 通过 SCF 框架的 ProxyFactory 拿到一个远程代理,调用 gatewayapi 暴露的 IGatewayFluxGroupService。
这个接口负责的事情很关键:节点上下线、权重调整、注册状态判断。proxy 在节点扩缩容、warmup、流量迁移时都会调它。超时意味着这些动作没在预期时间内完成,个别节点数据出现不一致,告警顺理成章地刷了进来。
SCF 客户端的接收超时配的是 3 秒。
也就是说,一次 RPC 调用如果 3 秒内没回来,proxy 这边就直接判它超时、走异常分支。几十次超时,就是几十次没回来。
问题来了:它为什么没回来?
🔍 第一步:从调用方看,就是接口超时
先看调用方 proxy 的日志。很干净,也很绝望:

从调用方看就是接口超时——没有异常堆栈,没有上游错误码:
调用 gatewayapi 超时,cluster=xxx fluxGroup=xxx ip=xxx没有异常堆栈,没有上游错误码,就是一句”超时”。调用方能告诉你的全部信息就是:我在 3 秒内没收到你的响应。
这其实是一个很常见的排查困境——调用方的日志只能证明”问题存在”,不能证明”问题在哪”。就像你打电话对方没接,你只知道没人接,不知道对方是在洗澡、在开会、还是手机掉了。
所以第一步的方向很明确:去服务方 gatewayapi 看它在那 3 秒里到底在干什么。
🔍 第二步:从服务方看,慢在了 DB 查询
gatewayapi 的日志就丰富多了。以 addNode 这个方法为例,它的核心逻辑其实非常简单——一次 DB 查询 + 一次 Consul 写入:
// GatewayFluxGroupService.addNode()
public BaseResponse<Boolean> addNode(AddNodeRequest request) throws Exception {
// 1. 先查 DB:这个流量组绑了哪些网关 upstream
List<UpstreamFluxGroupRelation> relations = upstreamFluxGroupRelationService
.listByFluxGroup(request.getClusterName(),
request.getEnv().getId(),
request.getFluxGroupName());
// 2. 再写 Consul:把节点信息写到每个 upstream 对应的 KV
for (UpstreamFluxGroupRelation relation : relations) {
String gatewayKey = ConsulKeyUtil.getGatewayUpstreamKey(...);
consulService.set(gatewayKey, JSON.toJSONString(val), request.getEnv());
}
return BaseResponse.createSuccess(true);
}正常情况下,两步都是毫秒级——DB 查询带索引,Consul 是本机房 HTTP KV 存储。一个请求正常几十毫秒就回来了。
但那天异常时段的日志显示:几十次 DB 查询的耗时超过了 2 秒。一次 DB 查询 2 秒,再加 Consul 写入,整个接口就奔着 3 秒去了,正好踩在客户端的超时线上。

服务方的日志把问题缩小到了一个非常具体的范围:查询一次 DB、执行一次 Consul,正常毫秒级完成,但异常时段这几十次 DB 查询超过了 2 秒,直接把整个接口拖过了 3 秒超时线。
正常:DB ~20ms + Consul ~30ms = ~50ms ✅
异常:DB ~2000ms+ + Consul ~数百ms = ~3000ms → 超时 ❌到这里,问题已经被缩小到了一个非常具体的范围:DB 查询在异常时段变慢了。下一步就是去查 DB 为什么慢。
🔍 第三步:查 MySQL 慢 SQL,没有
既然是 DB 查询变慢,最直接的怀疑对象就是慢 SQL。
我去 DB 监控平台翻了异常时段的慢查询日志——什么都没有。慢 SQL 的阈值配的是 1 秒,异常时段那几十次超过 2 秒的查询,理论上应该被完整记录下来,但平台上一条都没有。
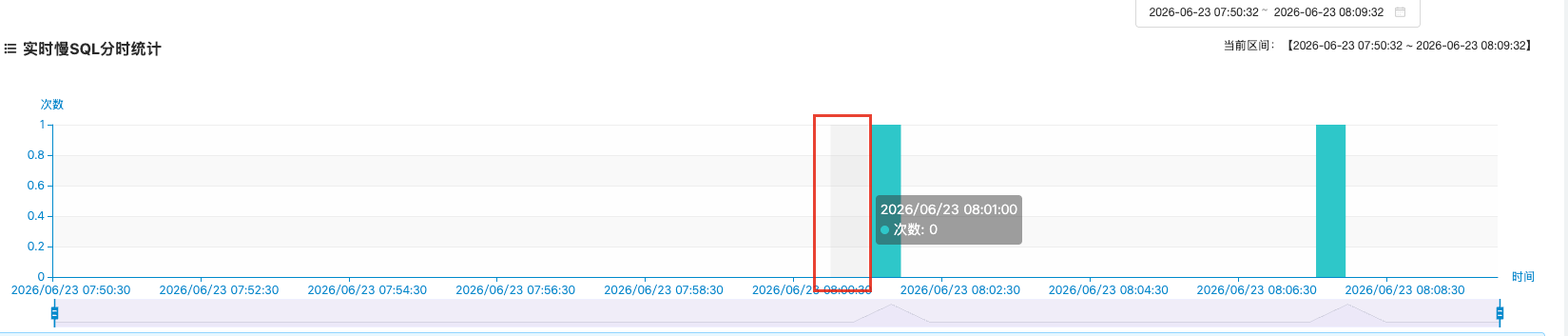
监控平台干干净净,这个表也有索引,DB 这条线索在这里断了。
再确认查询本身:listByFluxGroup 走的是 upstream_flux_group_relation 表,查询条件是 cluster_name + env + flux_group_name,这三个字段上是建了联合索引的。EXPLAIN 一看,走的也是 ref 级别,扫描行数是个位数。从 SQL 本身看,没有任何理由慢到 2 秒。
SQL 本身:走联合索引,ref 级别,扫描几行
慢 SQL 平台:异常时段 0 条记录
结论:不是慢 SQL,至少不是"能被慢日志捕获的那种慢 SQL"这就尴尬了。SQL 不慢,但查询确实慢了。这两种说法怎么并存?
我能想到的解释只有一个:查询在执行层慢了,但没慢到触发慢日志的判定条件,或者慢日志的采样本身有遗漏。但这只是推测,没有证据。
这条路也断了。
🔍 第四步:怀疑 JVM Full GC,没法证实
DB 这条线走不通,我换了个方向:会不会是 gatewayapi 的 JVM 在 Full GC,导致 STW(Stop-The-World),所有线程暂停,包括执行 DB 查询的线程?
STW 能完美解释为什么”DB 查询变慢了但慢日志没记录”——因为时间根本没花在 DB 上,而是花在 JVM 暂停上。查询发出之前或返回之后,JVM 卡住了 2 秒,从监控角度看就是”这次查询耗时 2 秒”。
但问题是:gatewayapi 没配 JVM 监控。
没有 GC 日志、没有 JMX 暴露、没有 Prometheus 接入。我连它用的是 CMS 还是 G1 都不知道,更别说去看那几分钟有没有 Full GC。
需要回答的问题:异常时段那几分钟,JVM 有没有 Full GC?
能回答的工具:GC 日志 / JMX / Prometheus
现实:都没有
结论:无法证实,也无法证伪这条路也断了,而且是断在最让人难受的地方——不是没有线索,而是没有工具。
🤔 最后的怀疑:MySQL 抖动,但慢 SQL 没记录
四条线走完,能排除的都排除了:
| 排查方向 | 结果 |
|---|---|
| 调用方 proxy 日志 | 只是超时,没有上游信息 |
| 服务方 gatewayapi 日志 | DB 查询耗时 >2s,定位到 DB 层 |
| MySQL 慢 SQL 平台 | 无记录,SQL 本身走索引,不慢 |
| JVM Full GC | 无监控,无法证实/证伪 |
最后我落在一个最没说服力、但也最可能的结论上:MySQL 抖动了。
数据库实例在某个瞬间因为底层 IO、缓冲池、或者别的什么原因出现短暂延迟,导致一批查询变慢。但这个抖动时间够短、幅度够边缘,既没触发慢 SQL 日志的记录,也没在 DB 监控平台上留下明显的指标异常。
这个结论的含金量约等于零——它只是一个”无法证伪”的推测,和一个”下次还会发生”的隐患。
✅ 没有结论,但要做点什么
排查没结论,但这不代表可以什么都不做。复盘后我给自己列了两个动作:
① 给 gatewayapi 配上 JVM 监控
这是最优先的事。没有 JVM 监控,排查 STW 只能靠猜,而猜是排查里最没价值的行为。
- 启动参数加上 GC 日志输出(
-Xlog:gc*:file=gc.log) - 接入 Prometheus + Grafana,暴露 JVM 指标(GC 次数/耗时、堆使用率、线程数)
- 配 Full GC 告警,单次耗时超过阈值就报出来
这样下次再出现”查询莫名变慢”,我至少能在 1 分钟内确认是不是 GC 在搞鬼。
② 给这次超时本身一个兜底
这次超时影响的是节点上下线操作,属于”最终一致”类的动作——这次没成功,下次再调一次也行。但 proxy 侧目前的处理是超时即异常、即告警,没有重试也没有降级。
更合理的做法是:对这类幂等的注册操作,超时后做一次有限重试(比如重试 1 次,间隔 500ms),重试还失败再告警。避免数据库一次短暂抖动就直接变成数据不一致和告警风暴。
💭 写在最后:没有结论的排查,也是排查
说实话,写这篇文章的时候我是有点别扭的。技术社区里大家爱看的都是”我查到了一个惊天大 Bug”、“一行代码引发的血案”——有起因、有推理、有真相、有修复,故事弧线完整。
但真实的排查里,有相当一部分是像我这次一样:查了一圈,每个方向都”看起来没问题”,最后只能落在一个含糊的推测上,然后去补监控、补兜底,等着它下次再发生。
我之所以还是把它写下来,是因为觉得这种”无果的排查”本身也有价值:
第一,它逼我承认监控的欠债。 JVM 没监控这件事,平时不痛不痒,一出事就是致命的——不是问题查不出来,是你连查的方向都没有。
第二,它提醒我”没有证据的反证”不等于”没有问题”。 DB 监控没记录慢 SQL,不能反证 DB 没慢;JVM 理论上不该 Full GC,不能反证它没 Full GC。
第三,“无果”不等于”无为”。 即便没找到根因,能补的兜底要补、能加的监控要加。这些动作的价值不在解决这次问题,而在让下一次问题发生时,你能比这次多看到一点东西。
下次如果再出现同样的超时,我希望我能打开 GC 日志看到一行 Full GC,或者打开 Grafana 看到一个堆使用率的尖峰——那时候我就能写一篇”有结论”的文章了。
但在此之前,这篇”没有结论”的记录,就先到这里。